



Entendendo a Modelagem de Dados: A Base de Tudo no Mundo dos DadosTítulo do post
MODELAGEMPT-BR
Lucas Lumertz
12/6/20244 min read
Eaee rapaziadinha! Todo mundo de boas? Espero verdadeiramente que sim. Falaremos, sobre um tópico no mundo dos dados super relevante, até para quem ainda utiliza somente planilhas, a modelagem de dados.
Quando falamos sobre dados, uma das primeiras coisas que precisamos aprender e lembrar, é como organizar todas essas informações disponíveis. E a modelagem de dados é a base para isso. Neste artigo, vou explicar o que é modelagem de dados, os diferentes tipos existentes e como escolher a mais adequada para cada situação. Porque como já conversamos anteriormente, tudo depende. Vamos explorar juntos de forma simples e prática? Let’s bora!
Vamos começar pelo início, nos primórdios da computação, os dados eram armazenados de forma desorganizada, o que dificultava bastante o acesso e o uso de forma eficiente desses dados. Foi aí que surgiu a necessidade de criar um sistema para organizar tudo. A modelagem de dados assim como o restante das coisas na área da tecnologia, evoluiu junto com o avanço da área e as necessidades do mercado. Com o aumento de informações e a complexidade dos sistemas, novas formas de modelagem foram criadas para acompanhar o ritmo.
Por exemplo, em 1970, o modelo relacional ganhou muita força, permitindo organizar dados em tabelas simples. Mais tarde, com o aumento da demanda, e a necessidade da análise de dados, surgiram modelos como o star schema e o snowflake, voltados para o armazenamento e consulta de grandes volumes de dados.
Afinal o que é a modelagem de dados Lucão? Vem comigo, vocês lembram da nossa suposta cidade dos artigos anteriores? Usaremos ela novamente aqui rsrs, a modelagem de dados é como desenhar o mapa de uma cidade antes de começar a construir as ruas e os prédios. É o processo de organizar e estruturar as informações para que possamos armazená-las e acessá-las de maneira mais eficiente. Isso ajuda a responder perguntas importantes, como: “Qual dado precisamos guardar?” e “Como esses dados se relacionam?”.
Exemplo: Imagine uma escola. Os dados são os alunos, professores e disciplinas. A modelagem vai organizar esses dados, conectando quem são os alunos, quem são os professores e quais disciplinas eles ensinam. Em diferentes tabelas.
Agora que já entendemos o conceito principal e um pouco da evolução por trás da modelagem de dados, vamos falar dos principais tipos de modelagem que existem atualmente no mercado:
1. Modelo Relacional:
Este modelo organiza os dados em tabelas com linhas e colunas. É como uma planilha gigante onde cada linha é um registro (exemplo: um cliente) e cada coluna é uma informação sobre ele (exemplo: nome, idade, e-mail). E quando necessário ter mais de uma tabela, elas normalemente vão ter relacionamentos entre si.
Exemplo: Pense numa tabela de contatos do celular. Cada linha é uma pessoa, e as colunas são informações como número de telefone, endereço e e-mail.
2. Star Schema:
O star schema (esquema em estrela) é muito usado para análise de dados. Ele organiza as informações em uma tabela central (tabela de fatos), conectada a outras tabelas menores (tabelas dimensionais), que ajudam a categorizar os dados.
A tabela fato, ela normalmente serve para armazenar as medidas associadas a observações ou alguns eventos. Ele pode armazenar por exemplo: ordens de venda, saldos, taxas de câmbio e muito mais.
Já as tabelas dimensão (uma ou mais, geralmente) irão auxiliar a tabela fato com as informações complementares.
A tabela fato vai carregar os acontecimentos da empresa, ela possui informações que podem ou não acabar se repetindo, inclusive mais de uma vez. Cada linha da tabela representa um fato.
Já na tabela dimensão possui informações em linhas únicas, que não irão se repetir, que vai nos permitir caracterizar, complementar, explicar, entender melhor o que temos na tabela fato.
Exemplo: Imagine que você é dono de uma loja. A tabela central armazena informações sobre vendas, enquanto as tabelas ao redor contêm detalhes sobre produtos, clientes e vendedores.
3. Snowflake Schema:
O snowflake schema (esquema em floco de neve) é uma versão mais detalhada do star schema. Nele, as tabelas dimensionais são divididas em subcategorias para organizar melhor ainda os dados.
Exemplo: No caso da loja, além de ter uma tabela de clientes, você poderia dividi-la em subcategorias, como “endereço” e “preferências de compra” e etc.
Okay, estou entendo Lucas, mas para que serve cada tipo de modelagem? É isso que vamos ver agora:
Relacional: Ideal para sistemas operacionais que precisam lidar com dados do dia a dia, como sistemas de gestão empresarial ou de atendimento ao cliente.
Star Schema: Focado em análise de dados, é usado em ferramentas de business intelligence para gerar relatórios e análises rápidas.
Snowflake Schema: Também voltado para análise, mas para cenários mais complexos e detalhados, com muitos dados interconectados.
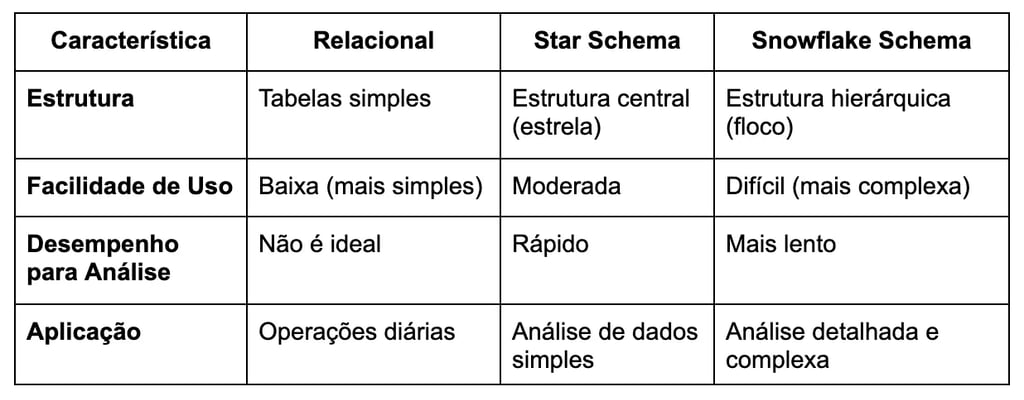
Abaixo criei uma tabela para poder exemplificar de uma forma mais simples as diferenças entre os diferentes modelos:
Ah Lucas, mas qual é o melhor? Como já disse bem no início, depende da situação e do problema que estamos querendo resolver, mas vou destacar alguns pontos para te auxiliar na decisão.
Modelo Relacional: Quando o foco é armazenar e acessar dados operacionais rapidamente, como em sistemas bancários ou ERPs, o relacional na maioria das vezes, é a melhor opção.
Star Schema: Para empresas que precisam de relatórios e análises rápidas sem muita complexidade, o star schema vai atender super bem, além de trazer bastante agilidade.
Snowflake Schema: Quando os dados são extremamente complexos e detalhados, e a organização precisa de consultas altamente específicas, é quando vamos utilizar o Snowflake schema.
Bom, acho que depois desse artigo rápido, fica bem evidente que a modelagem de dados é essencial para qualquer sistema que lide com informações. Ela ajuda vai ajudar a organizar, acessar e usar dados de uma forma muito mais eficiente. Escolher o modelo certo sempre vai depender do objetivo e da complexidade do projeto.
Se você quer algo simples e direto, o modelo relacional é uma ótima escolha. Para análises rápidas, o star schema é ideal. Já se precisa de algo mais detalhado, o snowflake schema é o caminho.
No final, a modelagem de dados é como desenhar o plano de uma casa antes de construir. Quanto mais bem planejada, mais eficiente será o resultado final. E você, já pensou em como está organizando os seus dados?
Enfim, eras isso pessoal, um abraço. E até o próximo tópico. 😊